I am a staff research scientist at FieldAI working with Dr. Shayegan Omidshafiei and Dr. Ali Agha to develop field foundation models. Before joining FieldAI, I was a research scientist at LG AI Research, where I developed large language model agents to navigate web environments with Prof. Honglak Lee.
I received my M.S./Ph.D. from MIT, studying multiagent reinforcement learning (doctoral thesis committee: Prof. Jonathan P. How, Prof. Jakob N. Foerster, and Prof. Pulkit Agrawal). Prior to my graduate study, I received a B.S. (summa cum laude) from Cornell and worked on computer vision research (advisor: Prof. Tsuhan Chen).
I am a recipient of the Kwanjeong Educational Foundation Fellowship, and have spent time at CMU-RI (advisor: Prof. Sebastian Scherer) and TTIC (advisor: Prof. Matthew R. Walter).
🤗 My up-to-date CV is available upon request.
📄 The publication list on this website is under construction. For the most recent papers, please refer to my Google Scholar profile.
Publication
Robot Learning
ELLIPSE: Evidential Learning for Robust Waypoints and Uncertainties Zihao Dong, Chanyoung Chung^*, Dong-Ki Kim^*, Mukhtar Maulimov^*, Xiangyun Meng, Harmish Khambhaita, Ali Agha, Amirreza Shaban Under Review, 2026
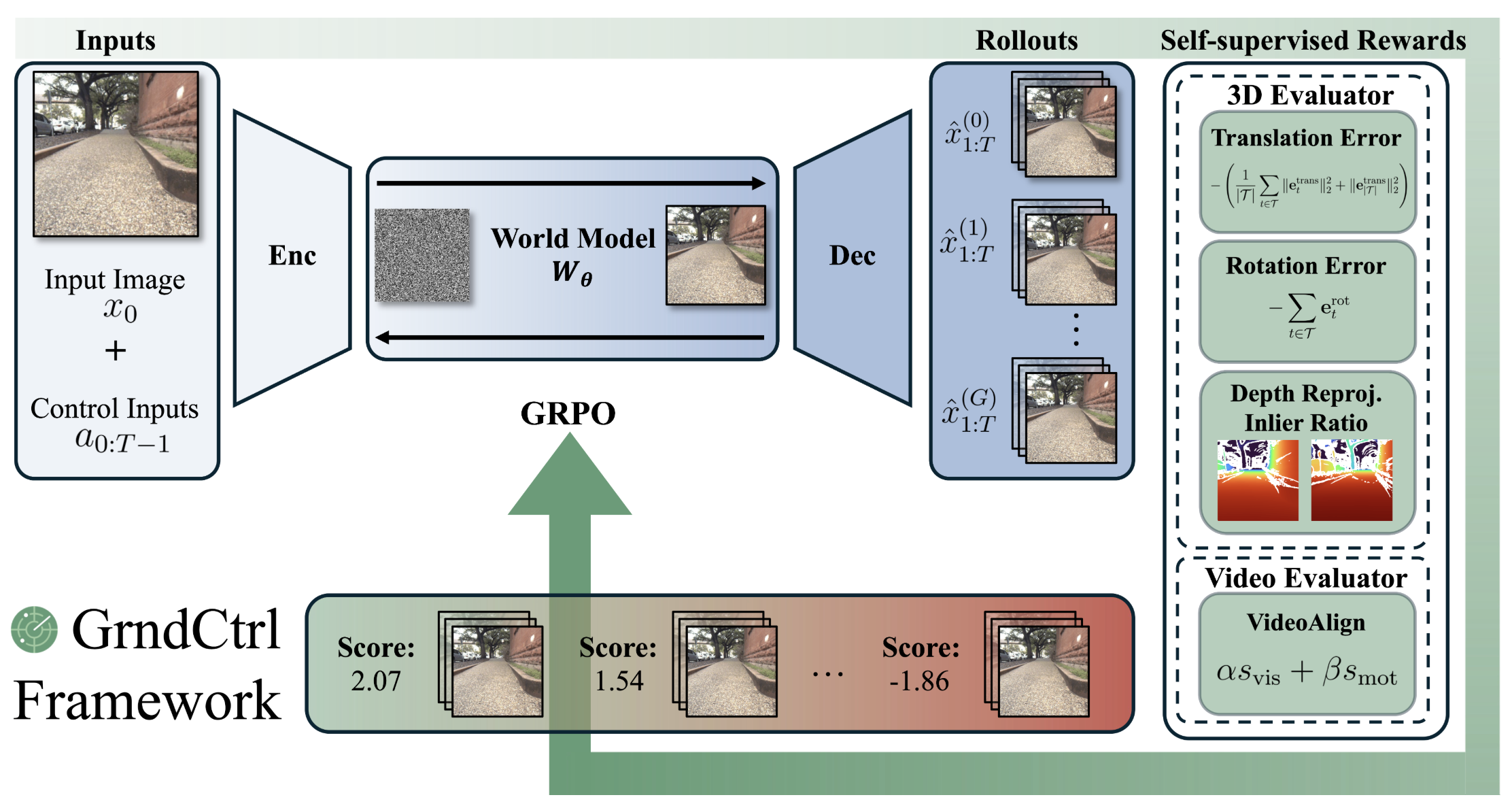
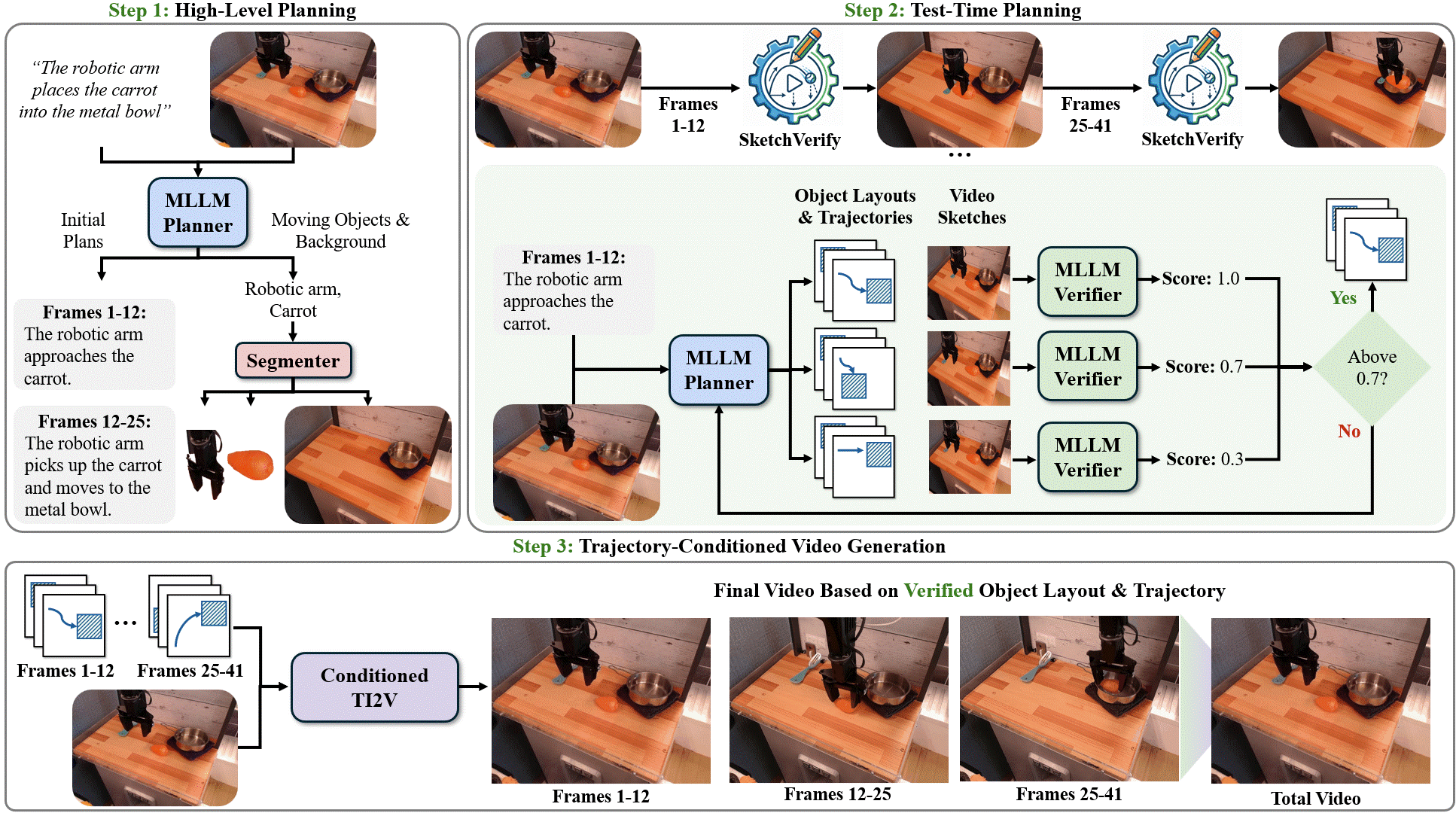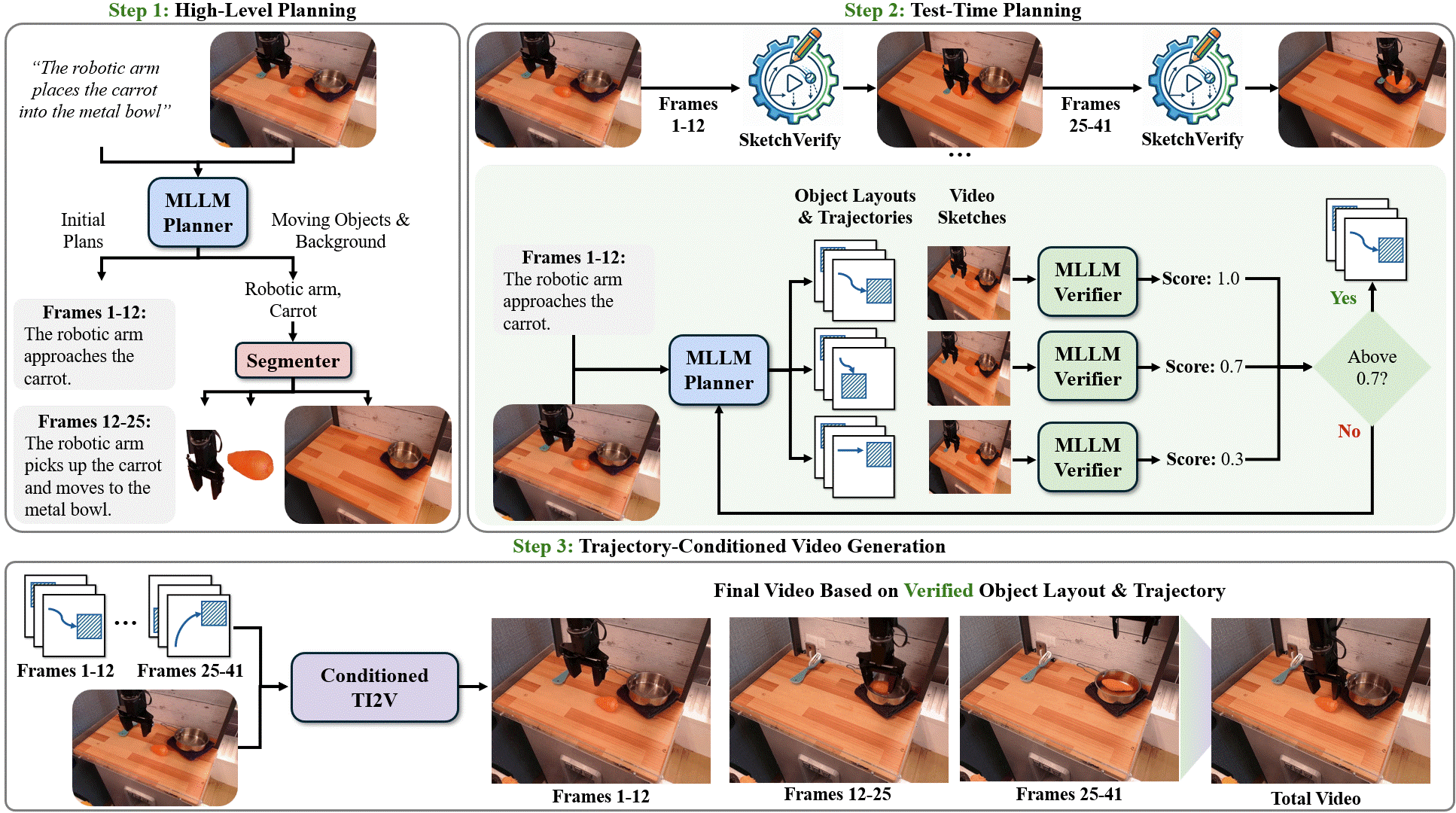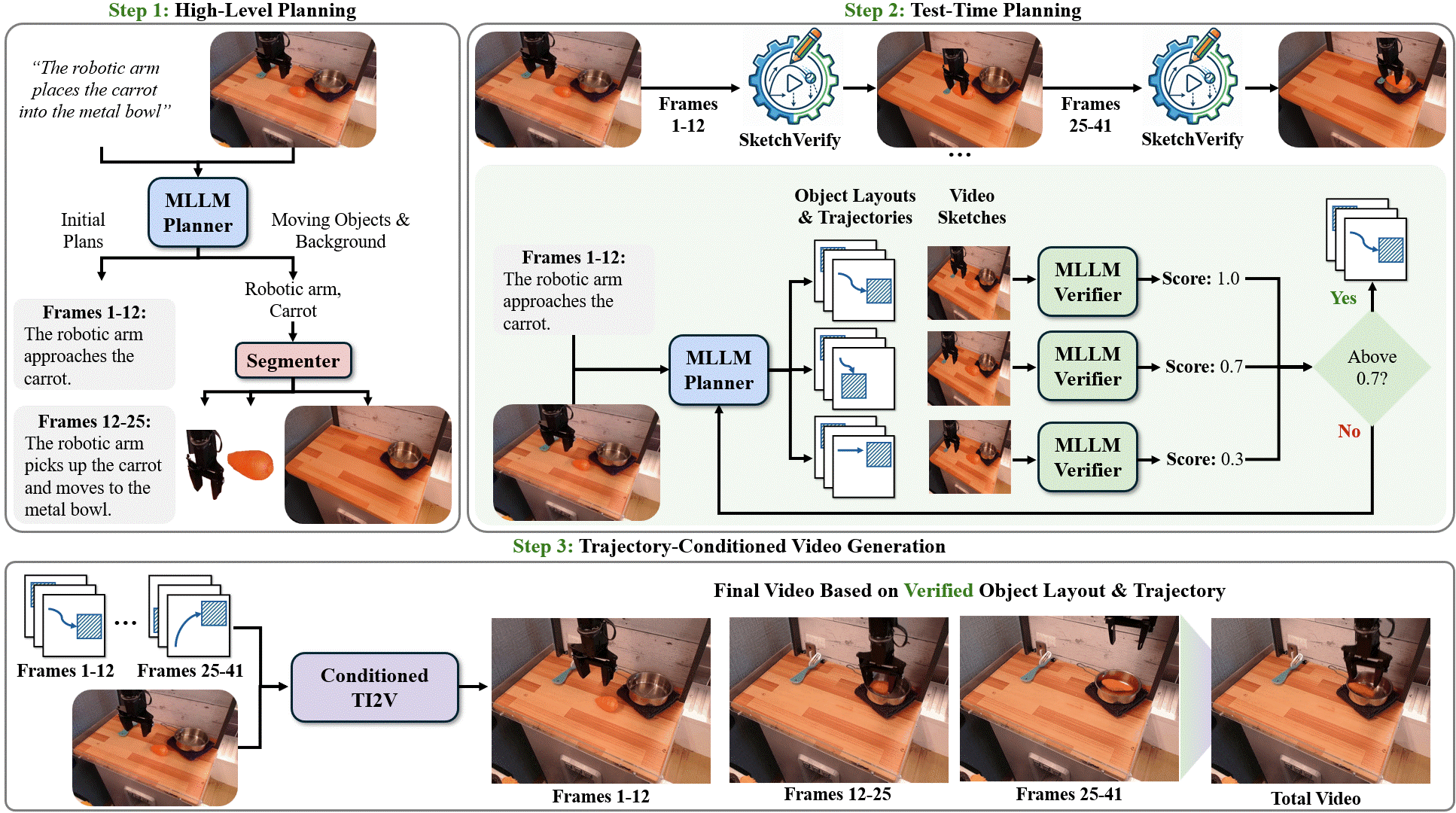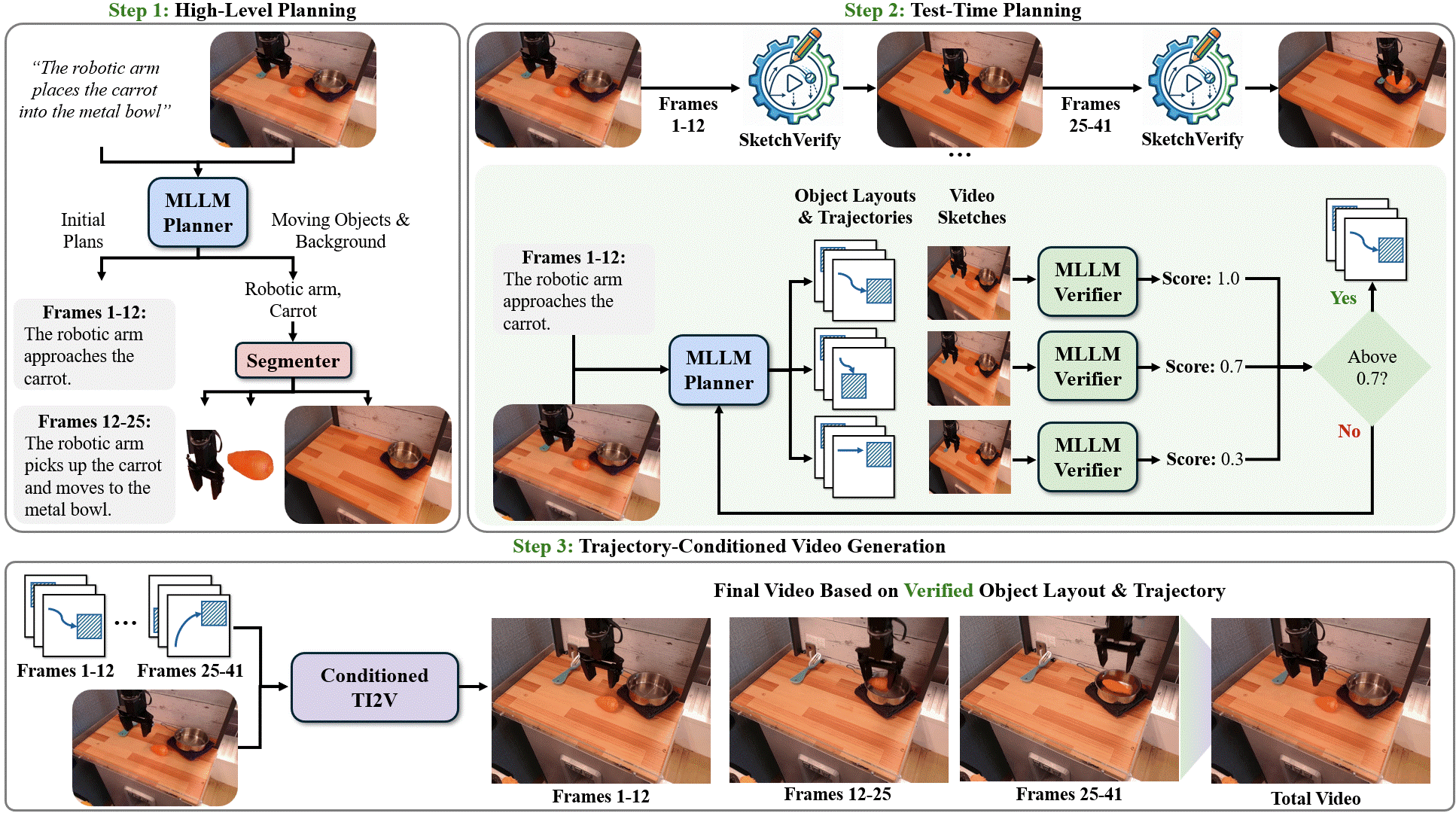
Delay-Aware Diffusion Policy: Bridging the Observation-Execution Gap in Dynamic Tasks Aileen Liao, Dong-Ki Kim, Max Olan Smith, Ali Agha, Shayegan Omidshafiei Under Review, 2026 GrndCtrl: Grounding World Models via Self-Supervised Reward Alignment Haoyang He, Jay Patrikar, Dong-Ki Kim, Max Smith, Daniel McGann, Ali Agha, Shayegan Omidshafiei, Sebastian Scherer Under Review, 2026 Planning with Sketch-Guided Verification for Physics-Aware Video Generation Yidong Huang, Zun Wang, Han Lin, Dong-Ki Kim, Shayegan Omidshafiei, Jaehong Yoon, Yue Zhang, Mohit Bansal Under Review, 2026
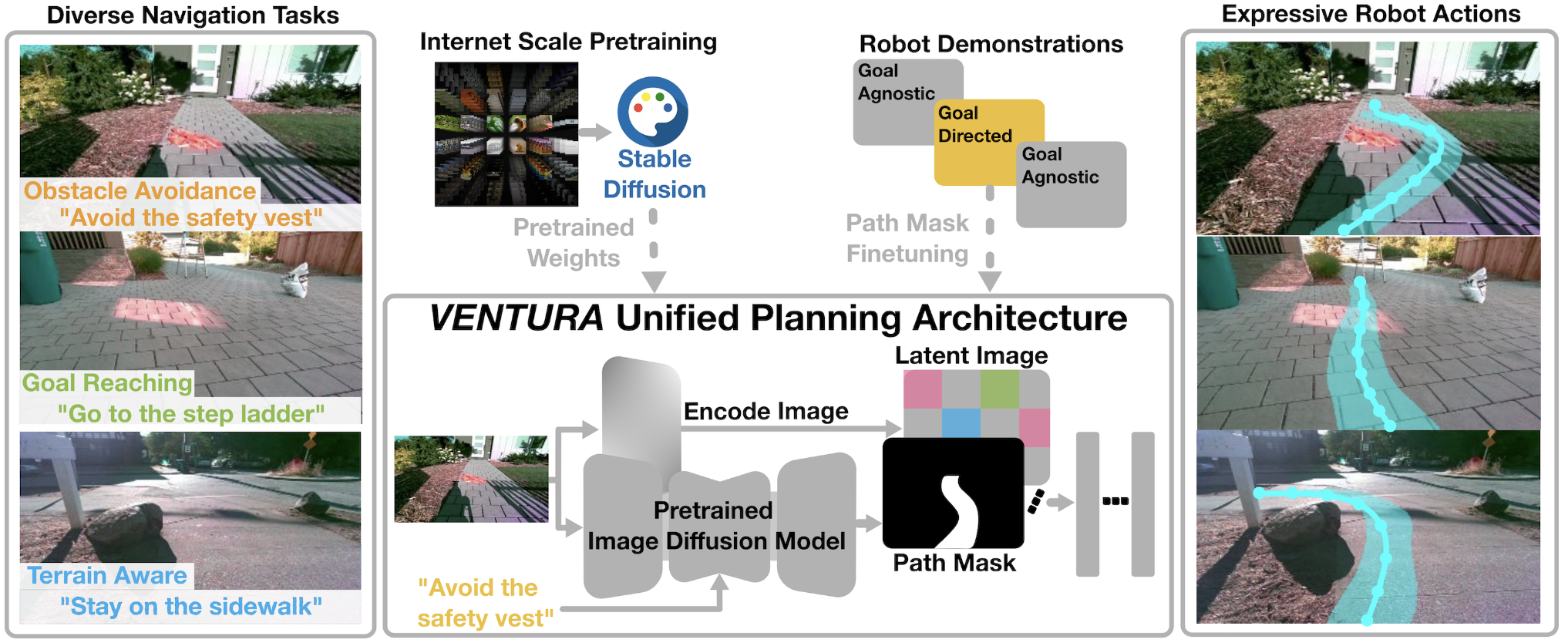
Don't Run with Scissors: Pruning Breaks VLA Models but They Can Be Recovered Jason Jabbour, Dong-Ki Kim, Max Olan Smith, Jay Patrikar, Radhika Ghosal, Youhui Wang, Ali Agha, Vijay Janapa Reddi, Shayegan Omidshafiei Under Review, 2026 VENTURA: Adapting Image Diffusion Models for Unified Task Conditioned Navigation Arthur Zhang, Xiangyun Meng, Luca Calliari, Dong-Ki Kim, Shayegan Omidshafiei, Joydeep Biswas, Ali Agha, Amirreza Shaban Under Review, 2026 StageACT: Stage-Conditioned Imitation for Robust Humanoid Door Opening Moonyoung Lee, Dong-Ki Kim, Jai Krishna Bandi, Max Smith, Aileen Liao, Ali Agha, Shayegan Omidshafiei Under Review, 2026
Enter the Mind Palace: Reasoning and Planning for Long-term Active Embodied Question Answering M. Fadhil Ginting, Dong-Ki Kim, Xiangyun Meng, Andrzej Reinke, Bandi Jai Krishna, Navid Kayhani, Oriana Peltzer, David D. Fan, Amirreza Shaban, Sung-Kyun Kim, Mykel J. Kochenderfer, Ali Agha, Shayegan Omidshafiei Conference on Robot Learning (CoRL), 2025
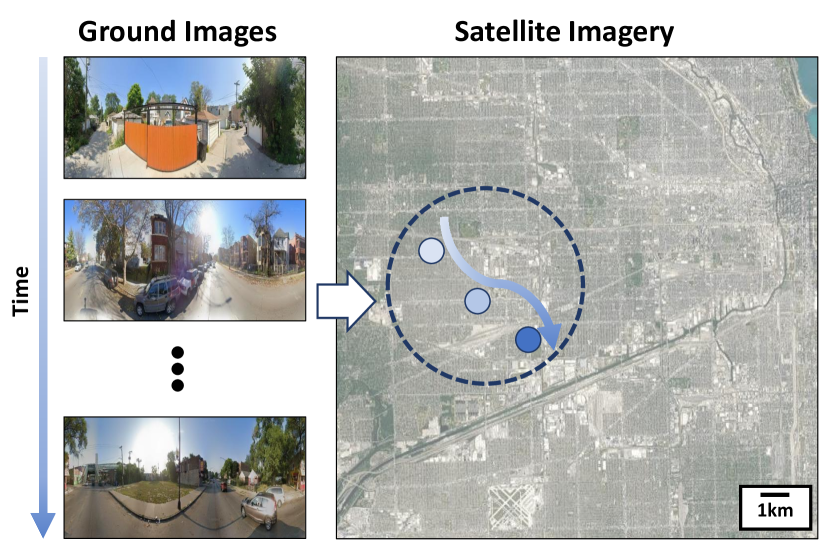
SayComply: Grounding Field Robotic Tasks in Operational Compliance through Retrieval-Based Language Models Muhammad Fadhil Ginting, Dong-Ki Kim, Sung-Kyun Kim, Bandi Jai Krishna, Mykel J. Kochenderfer, Shayegan Omidshafiei, Ali Agha International Conference on Robotics and Automation (ICRA), 2025 City-wide Street-to-Satellite Image Geolocalization of a Mobile Ground Agent Lena M. Downes, Dong-Ki Kim, Ted J. Steiner, Jonathan P. How International Conference on Intelligent Robots and Systems (IROS), 2022
Demonstration-Efficient Guided Policy Search via Imitation of Robust Tube MPC Andrea Tagliabue, Dong-Ki Kim, Michael Everett, Jonathan P. How International Conference on Robotics and Automation (ICRA), 2022
Satellite Image-based Localization via Learned Embeddings Dong-Ki Kim, Matthew R. Walter International Conference on Robotics and Automation (ICRA), 2017
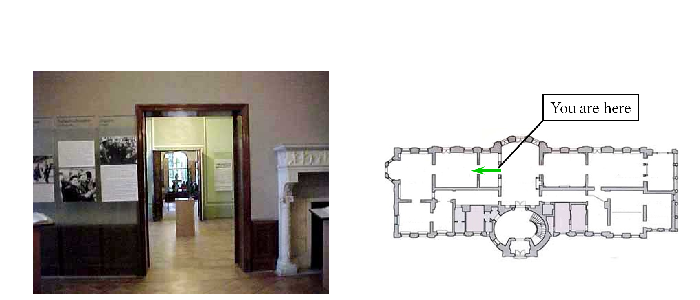
Season-Invariant Semantic Segmentation with A Deep Multimodal Network Dong-Ki Kim, Daniel Maturana, Masashi Uenoyama, Sebastian Scherer Field and Service Robotics (FSR), 2017 You Are Here: Mimicking the Human Thinking Process in Reading Floor-Plans Hang Chu, Dong-Ki Kim, Tsuhan Chen International Conference on Computer Vision (ICCV), 2015 Deep Neural Network for Real-Time Autonomous Indoor Navigation Dong-Ki Kim, Tsuhan Chen Technical Report, 2015 Reinforcement Learning
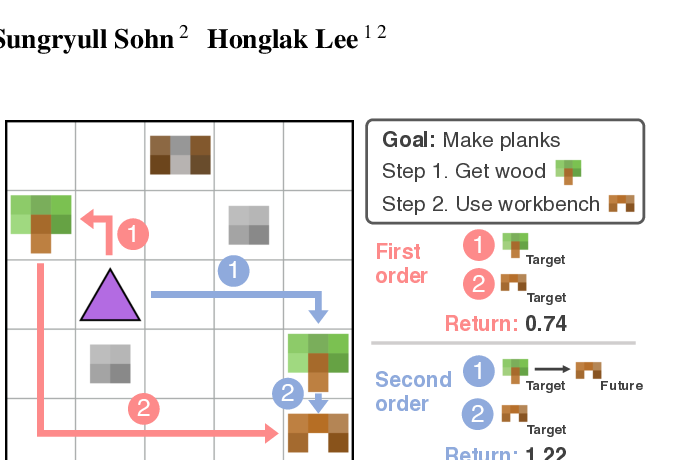
Learning Higher Order Skills that Efficiently Compose Anthony Z. Liu, Dong-Ki Kim, Sungryull Sohn, Honglak Lee International Conference on Machine Learning (ICML) Workshop, 2023 Game-Theoretical Perspectives on Active Equilibria: A Preferred Solution Concept over Nash Equilibria Dong-Ki Kim, Matthew Riemer, Miao Liu, Jakob N. Foerster, Gerald Tesauro, Jonathan P. How Conference on Robot Learning (CoRL) Workshop, 2022 🎉 Oral Presentation
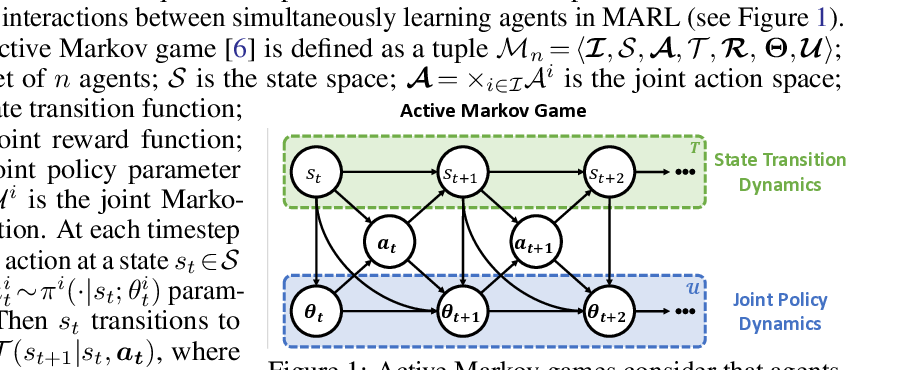
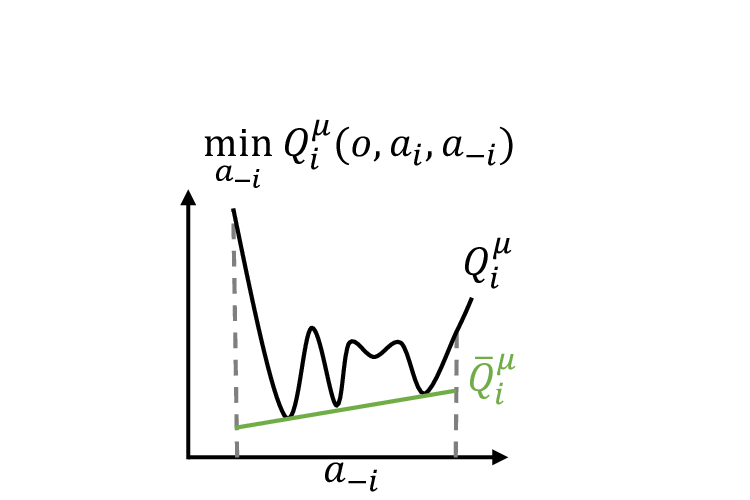
Influencing Long-Term Behavior in Multiagent Reinforcement Learning Dong-Ki Kim, Matthew Riemer, Miao Liu, Jakob N. Foerster, Michael Everett, Chuangchuang Sun, Gerald Tesauro, Jonathan P. How Neural Information Processing Systems (NeurIPS), 2022 ICLR 2022 Workshop 🎉 Spotlight ROMAX: Certifiably Robust Deep Multiagent Reinforcement Learning via Convex Relaxation Chuangchuang Sun, Dong-Ki Kim, Jonathan P. How International Conference on Robotics and Automation (ICRA), 2022 Context-Specific Representation Abstraction for Deep Option Learning Marwa Abdulhai, Dong-Ki Kim, Matthew Riemer, Miao Liu, Gerald Tesauro, Jonathan P. How Association for the Advancement of Artificial Intelligence (AAAI), 2022 A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning Dong-Ki Kim, Miao Liu, Matthew Riemer, Chuangchuang Sun, Marwa Abdulhai, Golnaz Habibi, Sebastian Lopez-Cot, Gerald Tesauro, Jonathan P. How International Conference on Machine Learning (ICML), 2021 FISAR: Forward Invariant Safe Reinforcement Learning with a Deep Neural Network-Based Optimizer Chuangchuang Sun, Dong-Ki Kim, Jonathan P. How International Conference on Robotics and Automation (ICRA), 2021 Learning Hierarchical Teaching in Cooperative Multiagent Reinforcement Learning Dong-Ki Kim, Miao Liu, Shayegan Omidshafiei, Sebastian Lopez-Cot, Matthew Riemer, Golnaz Habibi, Gerald Tesauro, Sami Mourad, Murray Campbell, Jonathan P. How International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2020
Policy Distillation and Value Matching in Multiagent Reinforcement Learning Samir Wadhwania, Dong-Ki Kim, Shayegan Omidshafiei, Jonathan P. How International Conference on Intelligent Robots and Systems (IROS), 2019 Learning to Teach in Cooperative Multiagent Reinforcement Learning Shayegan Omidshafiei, Dong-Ki Kim, Miao Liu, Gerald Tesauro, Matthew Riemer, Christopher Amato, Murray Campbell, Jonathan P. How Association for the Advancement of Artificial Intelligence (AAAI), 2019 🎉 Outstanding Student Paper Honorable Mention Crossmodal Attentive Skill Learner Shayegan Omidshafiei*, Dong-Ki Kim*, Jason Pazis, Jonathan P. How International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2018 & Journal of Autonomous Agents and Multi-Agent Systems (JAAMAS), 2020 Large Language/Vision Models
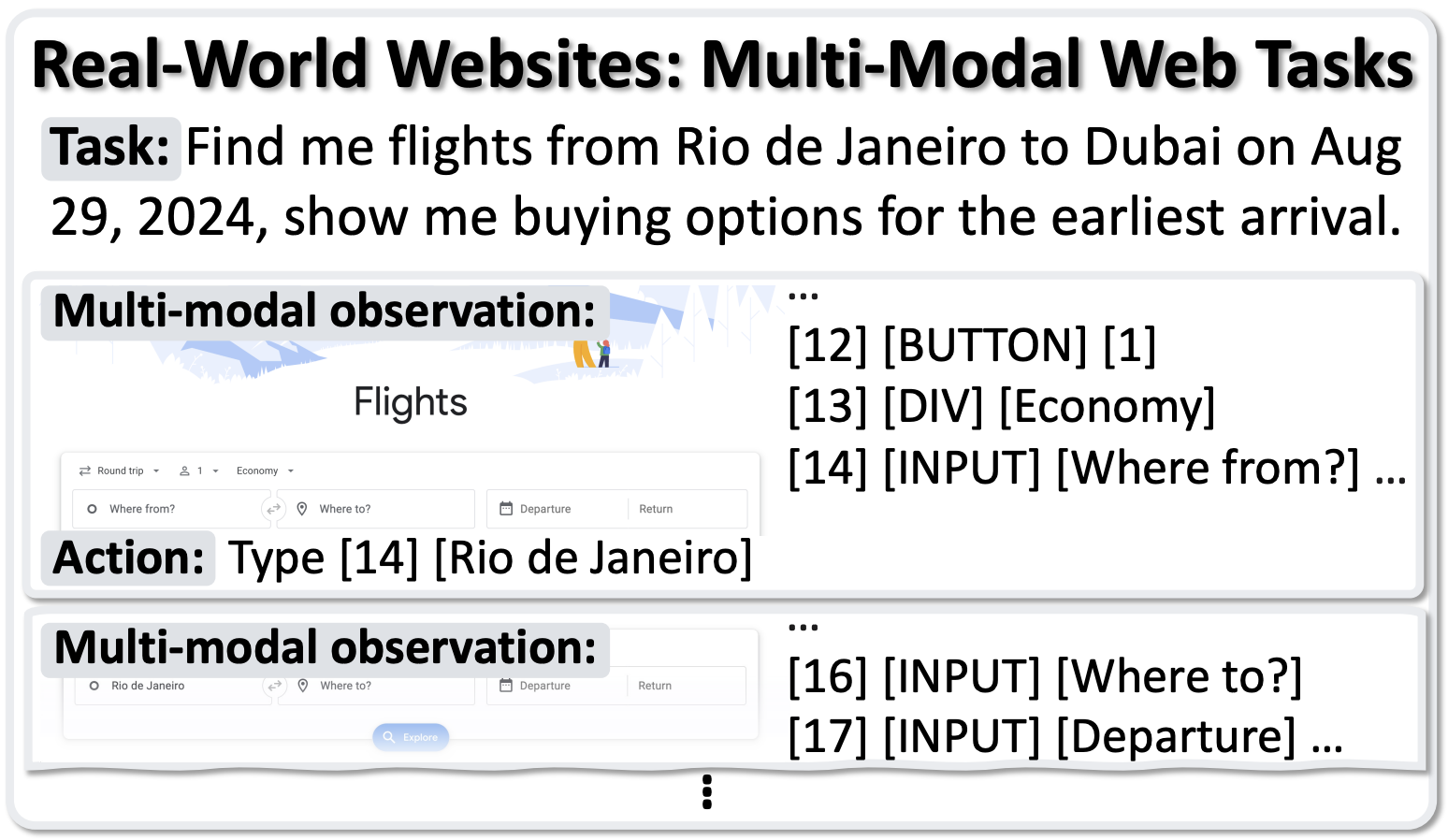
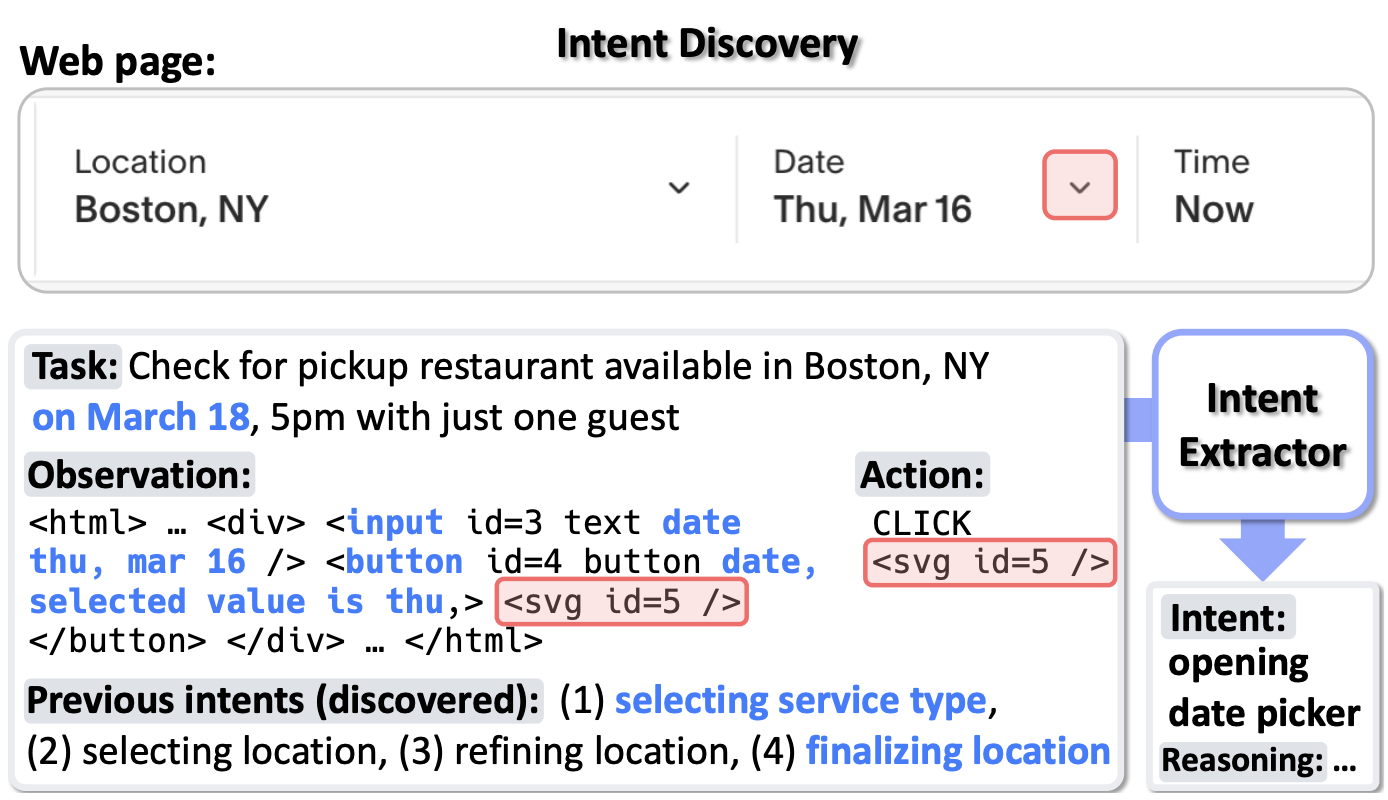
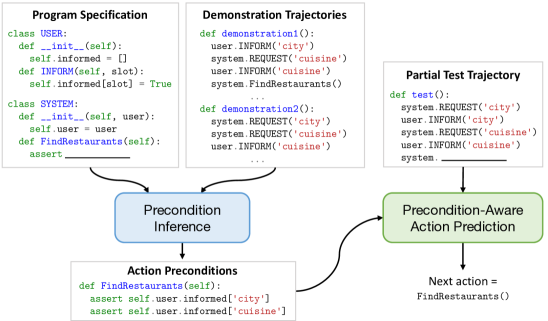
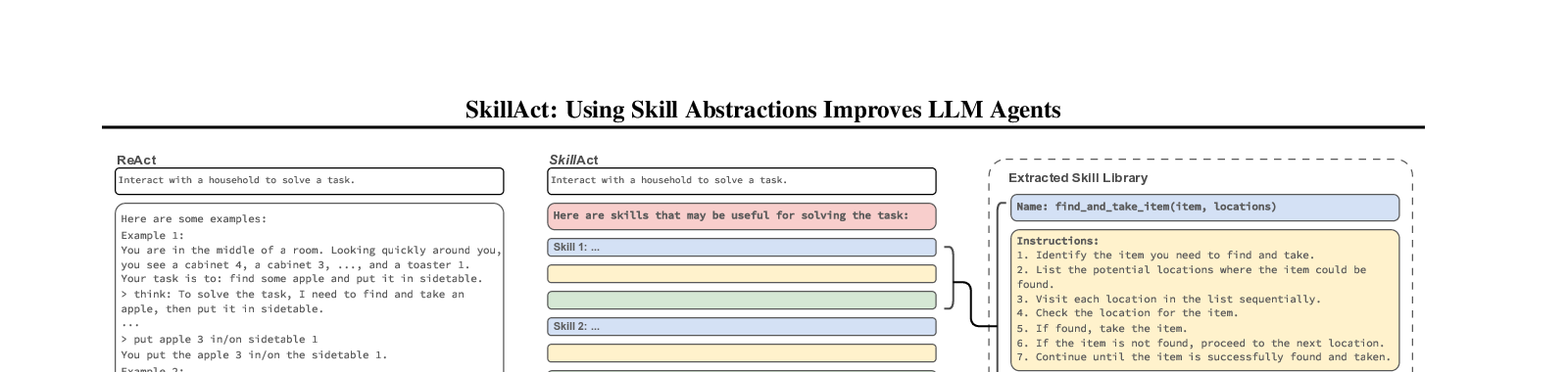
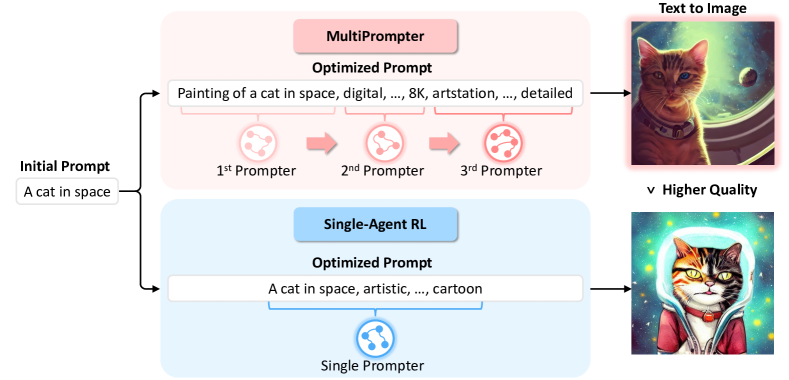
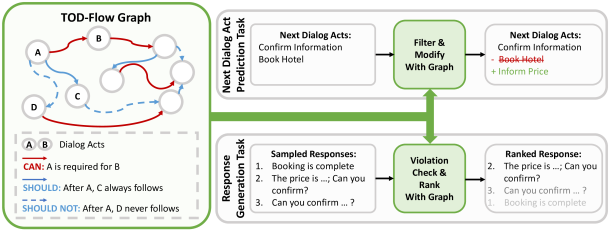
MONDAY: Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents Yunseok Jang*, Yeda Song*, Sungryull Sohn, Lajanugen Logeswaran, Tiange Luo, Dong-Ki Kim, Kyunghoon Bae, Honglak Lee Computer Vision and Pattern Recognition (CVPR), 2025 AutoGuide: Automated Generation and Selection of State-Aware Guidelines for Large Language Model Agents Yao Fu*, Dong-Ki Kim*, Jaekyeom Kim, Sungryull Sohn, Lajanugen Logeswaran, Kyunghoon Bae, Honglak Lee Neural Information Processing Systems (NeurIPS), 2024 Auto-Intent: Automated Intent Discovery and Self-Exploration for Large Language Model Agents Jaekyeom Kim, Dong-Ki Kim, Lajanugen Logeswaran, Sungryull Sohn, Honglak Lee Empirical Methods in Natural Language Processing (EMNLP), 2024 Code Models are Zero-shot Precondition Reasoners Lajanugen Logeswaran, Sungryull Sohn, Yiwei Lyu, Anthony Z. Liu, Dong-Ki Kim, Dongsub Shim, Moontae Lee, Honglak Lee North American Chapter of the Association for Computational Linguistics (NAACL), 2024 SkillAct: Using Skill Abstractions Improves LLM Agents Anthony Liu, Jongwook Choi, Sungryull Sohn, Yao Fu, Jaekyeom Kim, Dong-Ki Kim, Xinhe Wang, Jaewon Yoo, Honglak Lee International Conference on Machine Learning (ICML) Workshop, 2024 MultiPrompter: Cooperative Prompt Optimization with Multi-Agent Reinforcement Learning Dong-Ki Kim, Sungryull Sohn, Lajanugen Logeswaran, Dongsub Shim, Honglak Lee Neural Information Processing Systems (NeurIPS) Workshop, 2023 🎉 Spotlight TOD-Flow: Modeling the Structure of Task-Oriented Dialogues Sungryull Sohn, Yiwei Lyu, Anthony Z. Liu, Lajanugen Logeswaran, Dong-Ki Kim, Dongsub Shim, Honglak Lee Empirical Methods in Natural Language Processing (EMNLP), 2023